

Niemal połowa informacji generowanych przez AI zawiera co najmniej jeden istotny błąd






Wyniki uzyskane przez PBC są zbieżne z tymi przedstawionymi w badaniu zrealizowanym przez EBU i BBC (fot. Aerps.com/Unsplash.com)
Aż 46 proc. informacji generowanych przez popularne narzędzia AI – Perplexity, Gemini i ChatGPT – zawiera co najmniej jeden istotny błąd. Tak wynika z testów przeprowadzonych przez Polskie Badania Czytelnictwa.
PBC wykonało testy przy użyciu tych samych kryteriów oceny jakości informacji, co w zeszłorocznym badaniu "News Integrity in AI Assistants", zrealizowanym przez BBC i Europejską Unią Nadawców (EBU). Tamto badanie, przygotowane we współpracy z 22 organizacjami z 18 krajów, dotyczyło treści generowanych w 14 językach (nie uwzględniono języka polskiego). W ramach badania przeanalizowano 3 tys. odpowiedzi udzielonych przez Chata GPT, Copilot, Gemini i Perplexity. Pytano o kwestie dotyczące bieżących wydarzeń na świecie.
Aż 46 proc. odpowiedzi zawierało istotny błąd
Na naszym podwórku PBC przeprowadziło testy oparte na 60 zapytaniach kierowanych niezależnie do trzech asystentów AI – Chata GPT, Gemini oraz Perplexity.
Czytaj też: Jak sztuczna inteligencja może wspomóc redaktora. Porównanie popularnych modeli
Jak tłumaczy "Presserwisowi" prezeska PBC Renata Krzewska, w ramach testów sprawdzano, jak zagadnienia poruszane w polskiej prasie – m.in. w dziennikach ogólnopolskich i regionalnych, pismach dla kobiet oraz specjalistycznych – interpretowane są przez sztuczną inteligencję.
Wyniki uzyskane przez PBC są zbieżne z tymi przedstawionymi w badaniu zrealizowanym przez EBU i BBC. Na gruncie polskim aż 46 proc. wszystkich odpowiedzi wygenerowanych przez asystentów AI zawierało co najmniej jeden istotny błąd (odpowiedzi były niepoprawne, nie zawierały istotnych informacji lub były zbyt ogólne). W przypadku międzynarodowego badania BBC/EBU uzyskany wynik to 45 proc.
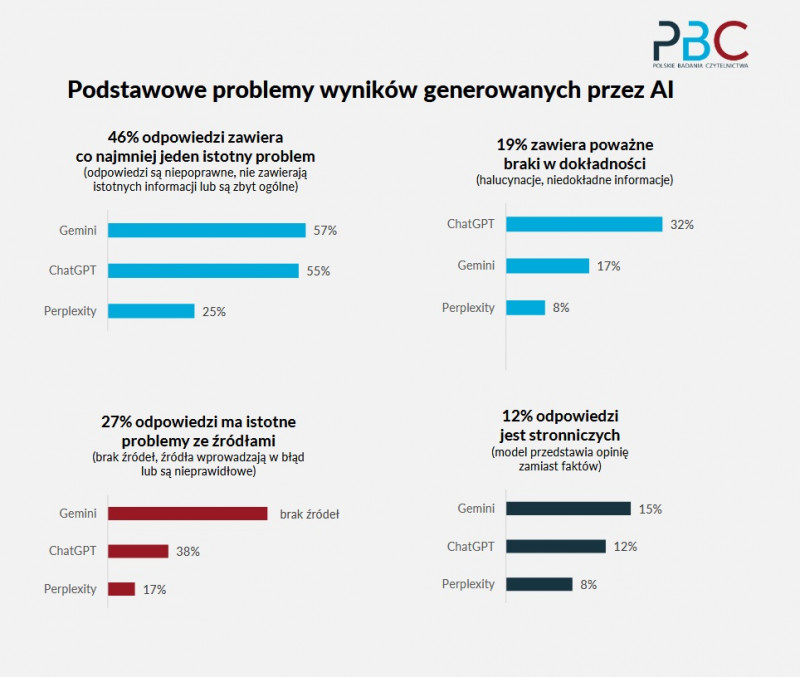
Jeśli spojrzeć na polskie testy dotyczące konkretnych asystentów AI, to aż 57 proc. odpowiedzi wygenerowanych przez Gemini miało co najmniej jeden poważny błąd. Problem ten dotyczył 55 proc. treści wygenerowanych przez Chat GPT i 25 proc. przez Perplexity.
Problemy ze źródłami i niedokładność
Według badania PBC 27 proc. treści wygenerowanych przez asystentów AI miało różnego rodzaju problemy ze źródłami – albo ich w ogóle nie podawały albo np. zawierały nieprawidłowe odnośniki. Według wyników badania BBC/EBU problem ten dotyczył 31 proc. testowanych treści.
Czytaj też: Wprowadzenie przez Google wyszukiwania AI uderzyło głównie w serwisy informacyjne
Wreszcie, testy Polskich Badań Czytelnictwa pokazały, że 19 proc. odpowiedzi zawiera niedokładne informacje lub wręcz halucynacje. W przypadku badania BBC/EBU wynik był nieznacznie wyższy – 20 proc.
Porównując polskie testy wygenerowane przez konkretnych asystentów AI, problem ten dotyczył 32 proc. treści podanych przez Chata GPT, 17 proc. przez Gemini i 8 proc. przez Perplexity.
Według PBC 12 proc. odpowiedzi uzyskanych w ramach testów było stronniczych (w przypadku Gemini – 15 proc., ChatGPT – 12 proc. i Perplexity – 8 proc.). W tej kategorii Polskie Badania Czytelnictwa nie robią porównań z badaniem zrealizowanym przez EBU i BBC.
"Halucynacje zdarzały się wielokrotnie"
Z polskich testów wynika również, iż wiarygodność AI zależy od tematyki. Jeśli chodzi o pytania dotyczące zagadnień poruszanych przez dzienniki ogólnopolskie, błędy pojawiały się w 33 proc. odpowiedzi. W przypadku tematyki związanej z prasą regionalną mowa o 44 proc.
Czytaj też: OpenAI szuka szefa działu badań nad zagrożeniami ze strony sztucznej inteligencji
Ale jeśli testujemy tematy, którymi żyją kobiece pisma luksusowe, mowa o 67 proc., a w przypadku zagadnień typowych dla prasy specjalistycznej (np. z zakresu zdrowia czy ogrodnictwa) mowa o 60 proc.
PBC przeprowadziło testy w oparciu o 60 zapytań kierowanych niezależnie do trzech asystentów AI – Chata GPT, Gemini oraz Perplexity (screen: PBC)
Prezeska PBC Renata Krzewska podaje przykład: – Dla mnie najbardziej druzgocąca była odpowiedź na temat wywiadu udzielonego przez polską profesor genetyki jednemu z pism kobiecych. Naukowczyni w wywiadzie tłumaczyła skomplikowane zagadnienia dotyczące dziedziczenia genetycznego. Gdy spytałam AI, o czym była ta rozmowa, dowiedziałam się, że o otyłości. Innym razem uzyskaliśmy błędną odpowiedź na temat kosztów remontu na lokalnym rynku. AI podało kilkukrotnie wyższą cenę niż rzeczywista. Takie halucynacje zdarzały się wielokrotnie – opowiada Renata Krzewska.
Nowy trend na międzynarodowym rynku prasowym
W trakcie wtorkowego webinaru, podczas którego zaprezentowano wyniki badania, przedstawiciele kilku polskich wydawnictw dyskutowali, jak w dobie AI i algorytmów zatrzymać przy sobie czytelników. Większość zgodziła się, że kluczowe jest dbanie o jakość materiałów, walka o subskrybentów oraz kierowanie odbiorców bezpośrednio do własnych treści prasowych.
Czytaj też: Komisja Europejska nakazuje platformie X zachowanie dokumentów Groka do końca 2026 roku
Na nowy trend na międzynarodowym rynku prasowym zwróciła uwagę Anna Dygasiewicz-Piwko, Head of Press Monetization Hub w RASP. Mówiła o uruchamianych przez wydawców asystentach AI, którzy odpowiadają na pytania zadane przez użytkowników serwisu. Takie narzędzie wprowadziły m.in. "Financial Times" oraz "The Washington Post".
– Takie chatboty pracują tylko na treściach publikowanych przez wydawcę. Poza umożliwieniem zadania pytania na konkretny temat, chatbot przygotowuje streszczenie artykułu czy też podsumowanie dnia. Naszemu czytelnikowi pozwala to zebrać informacje w sposób, do którego jest już przyzwyczajony – oceniła Anna Dygasiewicz-Piwko.
Prelegentami podczas webinaru byli także przedstawiciele Burdy Media Polska, Polska Press, ZPR Media, Agory oraz wydawnictwa Bauer.
Czytaj też: Coś więcej niż literki. Korektorzy o tym, czego nie wyłapie sztuczna inteligencja
(MZD, 17.01.2026)


