

Sprawdzamy najlepsze narzędzia do zamiany tekstu na realistyczny głos






Jeszcze nie tak dawno komputerowo wygenerowany głos brzmiał, jakby ktoś uczył mówić toster, dzisiaj jedynie specjalista jest w stanie odróżnić prawdziwy ludzki głos od wygenerowanego przez sztuczną inteligencję (fot. Andrea De Santis/Unsplash.com)
Przegląd najlepszych programów do zamiany tekstu na głos.
Badania wskazują, że głos zdominuje codzienne interakcje. Obsługa komputerów, notebooków i smartfonów ewoluuje od klikania do konwersacji głosowej. Zamiast klikać, będziemy rozmawiać – to consensus futurystów. Już dzisiaj, według badania RingCentral, 80 proc. pracowników wolałoby interakcję głosem z urządzeniami niż tradycyjne interfejsy.
Z ubiegłorocznych badań firmy Synthesia wynika, że liczba cyfrowych asystentów głosowych (na przykład Apple Siri czy Google Assistant) przekroczyła 8,4 mld, czyli jest ich więcej, niż liczy cała populacja Ziemi.
Historycznie rozpoznawanie mowy oraz generowanie głosu to technologie, nad którymi naukowcy pracują od lat 50. ubiegłego wieku. Pod koniec lat 80. na rynku pojawiły się całkiem sprawne czytniki ekranu dla niewidomych. Ich główną wadą było nieznośne, robotyczne brzmienie. Pierwsze komercyjne systemy rozpoznawania głosu to koniec lat 90., gdy pojawił się Dragon NaturallySpeaking. Umożliwiał dyktowanie tekstu komputerowi, ale wymagał treningu głosu i był bardzo wrażliwy na jakiekolwiek zakłócenia, np. rozmowę obok czy grające w tle radio.
Równolegle trwały prace nad rozwiązaniami generującymi głos na podstawie tekstu. Jednak od tego czasu technologia rozpoznawania mowy, ale również jej generowania, przeszła pełną metamorfozę i z niszy dla fanów nowych technologii stała się codziennie używaną przez miliony ludzi. Obecnie globalny rynek zamiany głosu w tekst wyceniany jest na blisko 5 mld dol. Ostrożne prognozy sugerują, że wzrośnie do 10 mld dol. w ciągu następnych czterech lat, a optymiści przewidują, że nawet do 25 mld dol.
GŁOS JAK ŻYWY
Szczególnie spektakularnie wyglądają obecne osiągnięcia zamiany tekstu w głos (text to speech). Droga, jaką przeszła technologia syntezy ludzkiego głosu, jest niesamowita. Jeszcze nie tak dawno komputerowo wygenerowany głos brzmiał, jakby ktoś uczył mówić toster, dzisiaj jedynie specjalista jest w stanie odróżnić prawdziwy ludzki głos od wygenerowanego przez sztuczną inteligencję. Ba, nauczyliśmy się już interpretować emocje, szeptać, krzyczeć, a nawet klonować głosy.
Kluczem jest rewolucja w sztucznej inteligencji, a konkretnie technologia, którą nazywamy Neural Text to Speech (NTTS). Stare systemy składały wyrazy z pojedynczych sylab, trochę jak z klocków, i dlatego brzmiało to tak sztucznie. Stosowany obecnie system neuronowy działa zupełnie inaczej – nie składa gotowych dźwięków, tylko generuje je od zera. Współczesne odtwarzacze mowy analizują całe napisane zdanie, rozumieją jego kontekst, a następnie tworzą falę dźwiękową, naśladując naturalną intonację, rytm mowy, a nawet branie oddechu między słowami. Jednym słowem, sztuczna inteligencja nauczyła się rozumieć, co mówi, a nie tylko bezmyślnie odczytywać znaki.
ELEVENREADER
W 2022 roku dwóch Polaków – Mateusz „Mati” Staniszewski oraz Piotr Dąbkowski – postanowiło zrealizować swoje marzenie z liceum i stworzyć oprogramowanie, które będzie tworzyło naturalnie brzmiący ludzki głos. W czasach licealnych bardzo denerwował ich monotonny głos lektora czytającego znudzonym tonem dialogi w zagranicznych filmach. Obydwaj po studiach kontynuowali swoje kariery w znanych amerykańskich firmach: Palantir (Staniszewski) i Google (Dąbkowski). Tak powstał startup ElevenLabs, którego oprogramowanie uważane jest dzisiaj za szczyt osiągnięć w dziedzinie generowania głosu. Technologia stojąca za ich rozwiązaniem nie tylko potrafi odczytać brzmienie głosu, ale też nadać mu ładunek emocjonalny. Dzięki temu ten sam akapit może brzmieć jak radosna wiadomość, smutne wyznanie lub beznamiętny, neutralny komunikat z lotniska.
Po stworzeniu doskonałej technologii, podobnie jak konkurencja, w 2025 roku wprowadzili na rynek aplikację ElevenReader, czyli konsumencki odtwarzacz TTS. Aplikacja czyta artykuły, PDF-y, e-booki, e-maile i wklejony tekst głosami ElevenLabs z możliwością wyboru kilkudziesięciu języków – w tym polskiego.
W gruncie rzeczy czytnik ElevenLabs to dość rozbudowana aplikacja działająca w dwóch modelach: bezpłatnym i płatnym. Pierwszy umożliwia odsłuchanie do dziesięciu godzin miesięcznie. Sporo, bo licząc, że średnie tempo normalnego mówienia to około 150 słów na minutę, daje to około 90 tys. słów, czyli – w zależności od języka – 400–450 tys. znaków tekstu. Można więc powiedzieć, że jest to przeciętnej grubości książka, 100 przeciętnych newsów albo kilkadziesiąt średniej długości artykułów. Do umiarkowanie częstego, codziennego użytkowania w zupełności wystarczy.

(screen: YouTube/Studio Motu)
Oprogramowanie startupu ElevenLabs, stworzonego przez dwóch Polaków: Mateusza „Matiego” Staniszewskiego oraz Piotra Dąbkowskiego, uważane jest dzisiaj za szczyt osiągnięć w dziedzinie generowania głosu.
ElevenReader możemy używać na dwa sposoby: pierwszy to udostępnienie tekstu w komputerze lub aplikacji mobilnej, który automatycznie jest zamieniany na mowę. Często w ten sposób korzystam z czytnika, jadąc samochodem lub komunikacją miejską. Po wyświetleniu na ekranie smartfona artykułu z internetu lub PDF-a, klikam ikonkę udostępnienia i wybieram ElevenReader. Aplikacja konwertuje podany tekst na dźwięk, usuwając zbędne elementy, np. reklamy lub inne elementy, które nie należą do tekstu, i po kilkunastu sekundach zaczyna go czytać.
Mogę odtwarzać tekst z różną prędkością: od normalnej (1x) do czterokrotnej (4x). Mogę też zwolnić prędkość czytania dwa razy (0,5x). Nie używam maksymalnej ani minimalnej prędkości, bo negatywnie wpływa na odbiór. Można też wybrać suwakiem wartości pośrednie. W moim przypadku sprawdza się przyspieszenie 1,3x. Tu ważna uwaga: zwiększenie prędkości odtwarzania wpływa na odejmowanie dostępnych minut w darmowym planie.
Olbrzymią zaletą jest możliwość wybrania rodzaju głosu. Do dyspozycji mamy zarówno polskie anonimowe głosy, jak np. Magdalena, jak i głosy aktorów, np. Piotra Fronczewskiego czy Jamesa Deana. Każdy, oprócz charakterystycznej barwy, różni się prędkością i intonacją. Mnie przy czytaniu newsów głosy aktorskie, np. Fronczewskiego, słabo się sprawdzają, bo są zbyt emocjonalne.
Ciekawą funkcją, obecnie w fazie beta, jest możliwość czatowania z czytanym tekstem. Klikam na dole ekranu na ikonkę chmurki i po chwili mogę zadać pytanie dotyczące słuchanego tekstu albo np. zlecić jego podsumowanie. Fajny gadżet, ale jak na razie mało dopracowany. Czat w czytniku po prostu słabo odpowiada na zadane pytania, ograniczając się do ogólników. Wydaje mi się też, że korzysta jedynie z informacji zawartych w tekście i nie pobiera dodatkowej wiedzy z internetu.
Mimo że odczytywane teksty są bardzo naturalne, uwzględniają interpunkcję, to na dłuższą metę czuje się pewną sztuczność. Wynika to z faktu, że trudno automatycznie dopasować różne formy wypowiadania tekstu. Po części wynika to z tego, że na przykład newsy pisane są pod kątem tradycyjnego czytania, a nie – jak w radiu czy telewizji – w specjalny sposób, chociażby unikając skomplikowanych strukturalnie zdań złożonych.
AUDIOBOOK NA WŁASNY UŻYTEK
W czytniku ElevenReader można też przesłać plik z komputera lub smartfona. Często korzystam z tej opcji do przeczytania na głos własnych tekstów. Wskazuję plik i po chwili jest on odczytywany wybranym z biblioteki głosem. To doskonały sposób na wyłapanie błędów, problemów z narracją czy stylem swojego materiału. Można też wgrać plik ePub, czyli np. e-book, i w ten sposób własnoręcznie zamienić go w audiobook.
Co ciekawe, ElevenReader rozpoznaje rozdziały w książce, co ma znaczenie przy nawigacji w aplikacji mobilnej, bo możemy wybrać konkretny rozdział, podobnie jak w czytniku. Tę funkcję nieraz wykorzystuję przy większych artykułach, zamieniając w bezpłatnym Calibre (https://calibre-ebook.com) plik PDF na ePub. Dużo wygodniej jest wówczas nawigować po częściach dużej pracy.
Jakość tak stworzonego audiobooka jest, przynajmniej dla mnie, wystarczająca. Oczywiście, nawet jeśli będzie czytany głosem znanego aktora, to jakość nie będzie taka jak w profesjonalnym audiobooku. Ciekawym dodatkiem, z którego nie korzystałem, ale wiem, że używają go często studenci, jest możliwość zrobienia zdjęcia, np. artykułu, i dodanie go do czytnika, który rozpozna tekst i zamieni go na audio.
BIBLIOTEKA DO SŁUCHANIA
ElevenReader, podobnie jak inne aplikacje, ma też całkiem sporą bibliotekę gotowych do odsłuchania książek z serwisu WolneLektury.pl oraz audiobooków autorów, którzy zdecydowali się udostępnić swoje dzieła w tej formie. Niektóre z nich są za darmo, ich odsłuch nie odejmuje minut od limitu, ale za niektóre – jak w serwisach z audiobookami – trzeba zapłacić. Testowo sprawdziłem kilka audiobooków i z pewnością jakość, np. w przekazywaniu emocji, jest zdecydowanie lepsza niż w przypadku tekstów, które sami dodamy. Wynika to najprawdopodobniej z zupełnie innej metody tworzenia audiobooków z tekstu i możliwości użycia tzw. znaczników w tekście, które powodują, że czytany głos wyraża emocje. Takimi znacznikami mogą być np. [śmiech], [zdziwienie] etc. i można je dodawać tylko w serwisie ElevenLabs w przeglądarce, a więc przeznaczone są do profesjonalnego opracowywania audiobooków. Możliwość dodatkowej edycji materiału tekstowego do konwersji jest w płatnych planach ElevenReader.
SPEECHIFY
Bezpośrednim konkurentem ElevenReader jest aplikacja Speechify, niewątpliwie najpopularniejszy czytnik na świecie, szczególnie popularnym w Stanach Zjednoczonych. Używa go ponad 50 mln osób. Skąd taka popularność? Byli pierwsi na rynku, trafnie zdiagnozowali potrzeby użytkowników i postawili na marketing. Zrozumieli, że w większości przypadków najważniejsza nie jest idealna jakość głosu, tylko przekonanie ludzi, by zaczęli słuchać.
Genialnym posunięciem było dodanie głosów celebrytów. Dla wielu czytanie artykułu przez np. Snoop Doga może być absurdem, ale pamiętajmy o młodszym pokoleniu, dla którego akurat ten głos może być wystarczającym argumentem, by sięgnąć po dłuższy tekst. Nawiasem mówiąc, młodzi uczący się lub studiujący, szczególnie w USA, to jedna z największych i najwierniejszych grup użytkowników tego typu aplikacji.
Speechify również ma bezpłatny plan, zwany podstawowym, ale o wiele bardziej restrykcyjny. Można korzystać z zamiany tekstu z plików, np. PDF na głos, ale tylko do 100 minut miesięcznie. W planie podstawowym nie możemy skorzystać z głosów generowanych przez AI, a więc tych najlepszej jakości, i zdani jesteśmy na typowy głos. Niewątpliwą zaletą Speechify – i być może tu leży źródło jego popularności – jest mnogość opcji. Aplikacja integruje się z wszystkimi popularnymi wirtualnymi dyskami, a więc bardzo łatwo jest wskazać plik tekstowy do konwersji na audio z dysku Google’a, Dropboxa, a nawet z Kindle’a. Wystarczy zalogować się przez aplikację do swojego konta w Amazonie i wskazać e-book, którego chcemy posłuchać. Niestety możliwość zamiany tekstu na głos dotyczy jedynie niezabezpieczonych e-booków i dlatego nie posłuchamy książki kupionej w Amazonie, ale tej z polskiej księgarni – już tak. Można też z tekstu stworzyć bezpośrednio w aplikacji podsumowanie materiału czy po prostu podcast. Ten ostatni może być w stylu np. „Late Night Show” lub debaty dwóch osób. Studenci mają możliwość stworzenia quizów z podanego tekstu. Olbrzymią zaletą Speechify jest to, że wygenerowany dźwięk możemy wyeksportować, a to umożliwia na przykład przesłanie go innym osobom albo wysłuchanie na dowolnym urządzeniu. Raz wykorzystałem w ten sposób Speechify do zrobienia voiceover, czyli polskiej wersji językowej wideo z YouTube’a. Najpierw trzeba pobrać napisy z oryginalnego pliku z YouTube’a – doskonale nadaje się do tego popularny yt-dlp (https://github.com/yt-dlp/yt-dlp). Można też pobrać wideo z YouTube’a, a następnie zrobić transkrypcję mowy, wykorzystując do tego na przykład aplikację Whisper Transcription (https://apps.apple.com/pl/app/whisper-transcription/id1668083311?l=pl). Mając już transkrypcję, możemy wybrać dwie ścieżki: pierwsza i chyba najprostsza to dodanie transkryptu do Speechify, określenie języka źródłowego (tekstu) i docelowego audio. Speechify automatycznie przetłumaczy transkrypcję i wygeneruje audio w wybranym, innym języku. Serwis używa Google Translate. Zalecam przetłumaczenie transkrypcji na docelowy język w jednym z popularnych chatów AI np. ChatGPT, Gemini czy Grok i następnie już gotowy transkrypt dodaję do Speechify, by wygenerowało audio. Oczywiście w tak prosty sposób zrobimy voiceover do filmu, gdzie występuje tylko narrator, ale już tam, gdzie jest rozmowa, tak łatwo pewnie nie będzie.
NATURALREADER
NaturalReader to kolejna wszechstronna aplikacja do syntezy mowy, z ciekawym modelem subskrypcyjnym. Dla osoby pracującej w mediach, gdzie czas na czytanie jest ograniczony, a potrzeba szybkiego odsłuchu rośnie, bezpłatna wersja NaturalReader jest praktycznym, choć ograniczonym narzędziem. Możemy w niej wykonać podstawową konwersję tekstu na głos za pomocą syntetycznych głosów, które – chociaż brzmią komputerowo – dobrze sobie radzą z prostymi polskimi i angielskimi tekstami.
Dzięki temu posiadacze bezpłatnej wersji mogą po wyjściu z konferencji wgrać plik z notatkami lub zrobić zdjęcie informacji prasowej i wracając do redakcji, odsłuchać w odtwarzaczu NaturalReader. Olbrzymią zaletą bezpłatnej wersji jest nielimitowane użycie syntetycznych głosów. W porównaniu z tymi profesjonalnymi brzmią okropnie, ale do odczytania notatek czy krótkich informacji w zupełności wystarczą. W darmowym planie jest też 20 tys. znaków (czyli około 20 minut) z głosami premium.
Płatne plany dają nam o wiele więcej możliwości, w tym np. pobieranie pliku mp3. Do zalet NaturalReader zaliczam bardzo prosty interfejs aplikacji mobilnej. Widoczna w prawym dolnym rogu ikonka „+” służy do wgrania pliku tekstowego, który po chwili jest zamieniony na audio. Jedna rzecz, przyznam szczerze, trochę mnie zaskoczyła – informacja, że pliki audio w wersjach płatnych można generować tylko na własny użytek. Do celów komercyjnych służy specjalna wersja NaturalReader Commercial, ale jej cena jest zdecydowanie wyższa – 99 dol. miesięcznie za 6 mln znaków. Dla porównania w ElevenLabs w komercyjnym planie Pro za 99 dol. otrzymujemy tylko 500 tys. znaków, ale płacimy za o wiele większe możliwości i zdecydowanie wyższą jakość.
DESCRIPT
Z dziennikarskiego punktu widzenia game changerem jest Descript. To profesjonalne studio do edycji audio i wideo, wspomagane sztuczną inteligencją i działające na bazie tekstu. Wyobraź sobie, że nagrywasz podcast i w trakcie rozmowy telefonicznej nagminnie ty albo twój rozmówca jąkacie się lub przeciągacie zgłoski. Descript stworzy transkrypcję twojego nagrania i wystarczy znaleźć w tekście i wskazać elementy do skasowania, a program automatycznie usunie je z nagrania, sklejając resztę w idealną całość. Na podobnej zasadzie, po sklonowaniu własnego głosu, możesz wstawiać fragmenty do rozmowy. Każdy, kto chociaż raz w życiu poprawiał nagranie audio, wie, że edycja audio, podobnie jak edycja tekstu w Wordzie, jest rewolucją w postprodukcji.
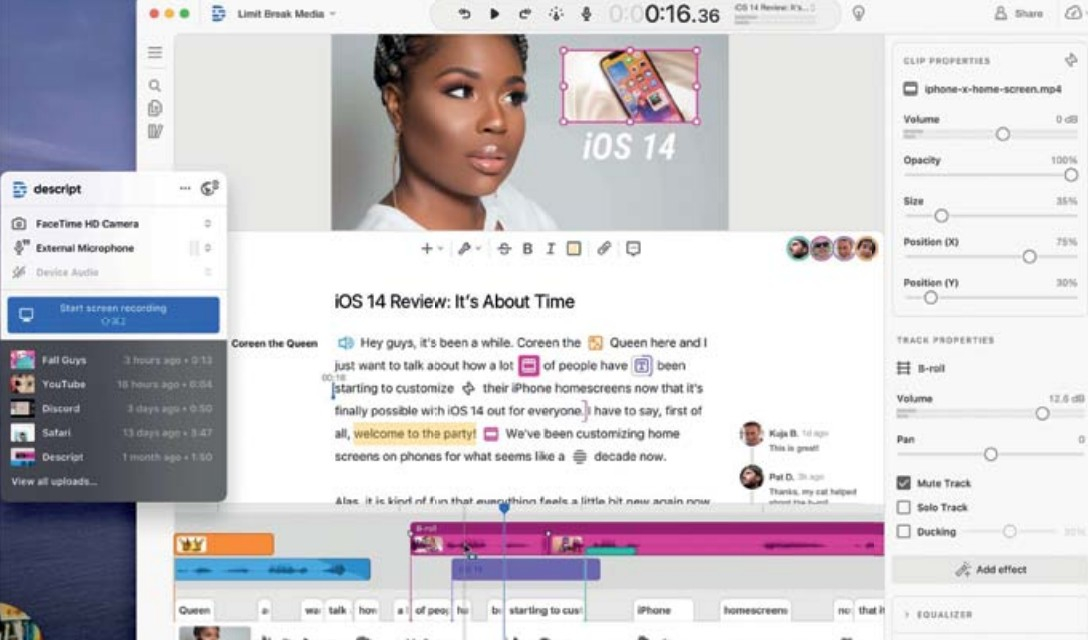
Descript to profesjonalne studio do edycji audio i wideo, wspomagane sztuczną inteligencją, które działa na bazie tekstu (screen: magazyn „Press”, nr 01-02/2026)
Descript to już wyższa półka. Przyda się na pewno twórcom podcastów czy youtuberom, ale nie dziennikarzowi, który chciałby jedynie zamienić długie artykuły na audio, by je odsłuchać podczas jazdy pociągiem.
KOLEJNA REWOLUCJA
Czytanie jest efektywniejsze od słuchania. Badania pokazują, że przeciętna prędkość cichego czytania to 240–280 słów na minutę, podczas gdy naturalna mowa to 150–190 słów na minutę. Przyspieszenie odsłuchu, nawet do 250 słów na minutę, w większości przypadków nie powoduje kłopotów ze zrozumieniem tekstu. Jeśli dodamy do tego fakt, że możemy podczas słuchania wykonywać inne czynności, np. jechać samochodem albo trenować na siłowni, to mamy odpowiedź, dlaczego czytniki audio są coraz popularniejsze. Tymczasem ta technologia jest dopiero we wczesnej fazie rozwoju. Gdy piszę te słowa, Apple i Google wprowadzają aplikacje do tłumaczenia rozmów na żywo. Wyobraźmy sobie: nie musimy znać perfekcyjnie żadnego języka obcego, by swobodnie rozmawiać z każdą osobą na świecie, każdy w swoim języku. To krok do kolejnej rewolucji w mediach: stworzenia formatu mediów wielojęzykowych, gdzie odbiorca z dowolnego miejsca na świecie przeczyta lub obejrzy wybraną wersję językową tekstu albo audio. Oczywiście to on wybierze, czy woli czytać, czy słuchać.
Audiotyzacja prasy następuje w szybkim tempie. Wiele tytułów prasowych oferuje możliwość odsłuchania artykułu. Badania wykazały, że około 9,95 proc. użytkowników korzysta z odtwarzaczy audio przy artykułach. 35 proc. użytkowników słucha treści audio przez ponad 2,5 minuty, czyli o wiele dłużej niż w przypadku tradycyjnych form oglądania strony internetowej. Ten proces będzie przyspieszał. Amazon Alexa od dawna oferuje odsłuchanie serwisu informacyjnego. Tymczasem technologia Text to Speech umożliwia stworzenie spersonalizowanej wersji audio, np. serwisu informacyjnego, odczytywanego przez ulubionego celebrytę.
GŁOS MILCZĄCYCH
W ubiegłym roku BBC Two wyemitowało film „The Jennings vs Alzheimer”, który odbił się głośnym echem na całym świecie. Film opowiada poruszającą historię rodziny Jennings z Wielkiej Brytanii, u której jako pierwszej na świecie zdiagnozowano dziedziczną, wczesną chorobę Alzheimera, co stało się asumptem do przełomowych badań nad tą chorobą. Główną bohaterką jest Carol Jennings, która będąc jeszcze młodą kobietą, zauważyła niepokojącą prawidłowość: jej ojciec i rodzeństwo zachorowali w stosunkowo wczesnym wieku na chorobę Alzheimera, co może sugerować jej genetyczne podłoże. Współpraca Carol, która też zachorowała, z naukowcami zaowocowała wykryciem mutacji genu, a w efekcie powstaniem leków spowalniających chorobę. W czasie realizacji filmu Carol była już w zaawansowanym stadium choroby i nie mogła mówić, dlatego twórcy filmu sklonowali jej głos i użyli go do odczytania jej zapisków.
To jeden z przykładów, jak technologia zamiany tekstu na mowę i sztuczna inteligencja zaczynają odgrywać ważną rolę w naszym życiu.
***
Ten tekst Stanisława M. Stanucha pochodzi z magazynu „Press” – wydanie nr 01-02/2026. Teraz udostępniliśmy go do przeczytania w całości.
„Press” do nabycia w salonach prasowych, App Store, Google Play, e-Kiosku lub online na E-sklep.press.pl.
Czytaj też: Numer na 30-lecie "Press": rozmowa z Miszczakiem, sylwetka Wysockiej-Schnepf i plemiona

Stanisław M. Stanuch


